 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2Former-V2: On-the-Fly Equivariant Attention with Linear Activation Memory
Jan 23, 2026Equivariant Graph Neural Networks (EGNNs) have become a widely used approach for modeling 3D atomistic systems. However, mainstream architectures face critical scalability bottlenecks due to the explicit construction of geometric features or dense tensor products on \textit{every} edge. To overcome this, we introduce \textbf{E2Former-V2}, a scalable architecture that integrates algebraic sparsity with hardware-aware execution. We first propose \textbf{E}quivariant \textbf{A}xis-\textbf{A}ligned \textbf{S}parsification (EAAS). EAAS builds on Wigner-$6j$ convolution by exploiting an $\mathrm{SO}(3) \rightarrow \mathrm{SO}(2)$ change of basis to transform computationally expensive dense tensor contractions into efficient, sparse parity re-indexing operations. Building on this representation, we introduce \textbf{On-the-Fly Equivariant Attention}, a fully node-centric mechanism implemented via a custom fused Triton kernel. By eliminating materialized edge tensors and maximizing SRAM utilization, our kernel achieves a \textbf{20$\times$ improvement in TFLOPS} compared to standard implementations. Extensive experiments on the SPICE and OMol25 datasets demonstrate that E2Former-V2 maintains comparable predictive performance while notably accelerating inference. This work demonstrates that large equivariant transformers can be trained efficiently using widely accessible GPU platforms. The code is avalible at https://github.com/IQuestLab/UBio-MolFM/tree/e2formerv2.
EntroCoT: Enhancing Chain-of-Thought via Adaptive Entropy-Guided Segmentation
Jan 08, 2026Chain-of-Thought (CoT) prompting has significantly enhanced the mathematical reasoning capabilities of Large Language Models. We find existing fine-tuning datasets frequently suffer from the "answer right but reasoning wrong" probelm, where correct final answers are derived from hallucinated, redundant, or logically invalid intermediate steps. This paper proposes EntroCoT, a unified framework for automatically identifying and refining low-quality CoT supervision traces. EntroCoT first proposes an entropy-based mechanism to segment the reasoning trace into multiple steps at uncertain junctures, and then introduces a Monte Carlo rollout-based mechanism to evaluate the marginal contribution of each step. By accurately filtering deceptive reasoning samples, EntroCoT constructs a high-quality dataset where every intermediate step in each reasoning trace facilitates the final answer. Extensive experiments on mathematical benchmarks demonstrate that fine-tuning on the subset constructed by EntroCoT consistently outperforms the baseslines of full-dataset supervision.
Scalable Machine Learning Force Fields for Macromolecular Systems Through Long-Range Aware Message Passing
Jan 07, 2026Machine learning force fields (MLFFs) have revolutionized molecular simulations by providing quantum mechanical accuracy at the speed of molecular mechanical computations. However, a fundamental reliance of these models on fixed-cutoff architectures limits their applicability to macromolecular systems where long-range interactions dominate. We demonstrate that this locality constraint causes force prediction errors to scale monotonically with system size, revealing a critical architectural bottleneck. To overcome this, we establish the systematically designed MolLR25 ({Mol}ecules with {L}ong-{R}ange effect) benchmark up to 1200 atoms, generated using high-fidelity DFT, and introduce E2Former-LSR, an equivariant transformer that explicitly integrates long-range attention blocks. E2Former-LSR exhibits stable error scaling, achieves superior fidelity in capturing non-covalent decay, and maintains precision on complex protein conformations. Crucially, its efficient design provides up to 30% speedup compared to purely local models. This work validates the necessity of non-local architectures for generalizable MLFFs, enabling high-fidelity molecular dynamics for large-scale chemical and biological systems.
Enabling AI Scientists to Recognize Innovation: A Domain-Agnostic Algorithm for Assessing Novelty
Mar 03, 2025



In the pursuit of Artificial General Intelligence (AGI), automating the generation and evaluation of novel research ideas is a key challenge in AI-driven scientific discovery. This paper presents Relative Neighbor Density (RND), a domain-agnostic algorithm for novelty assessment in research ideas that overcomes the limitations of existing approaches by analyzing the distribution patterns of semantic neighbors rather than simple distances. We first developed a scalable methodology to create validation datasets without expert labeling, addressing a fundamental challenge in novelty assessment. Using these datasets, we demonstrate that our RND algorithm achieves state-of-the-art (SOTA) performance in computer science (AUROC=0.808) and biomedical research (AUROC=0.757) domains. Most significantly, while SOTA models like Sonnet-3.7 and existing metrics show domain-specific performance degradation, RND maintains consistent effectiveness across domains, outperforming all benchmarks by a substantial margin (0.782 v.s. 0.597) on cross-domain evaluation. These results validate RND as a generalizable solution for automated novelty assessment in scientific research.
FedSSO: A Federated Server-Side Second-Order Optimization Algorithm
Jun 20, 2022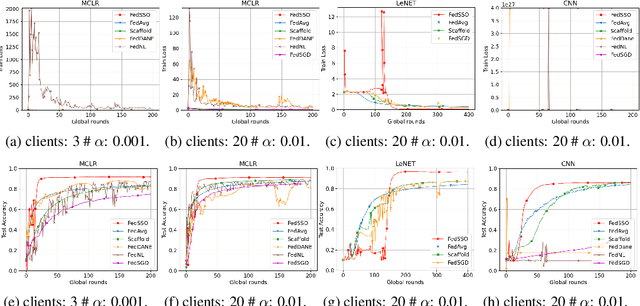
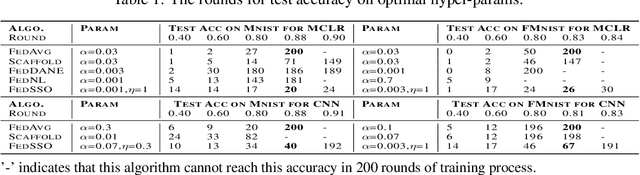
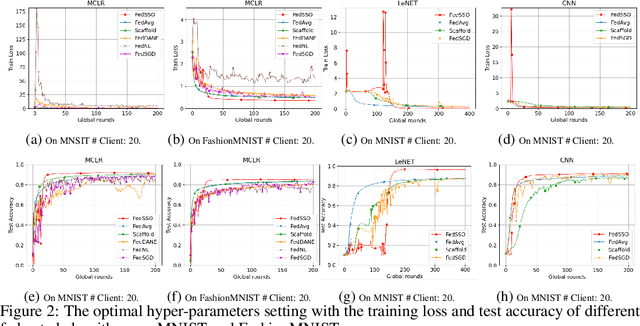

In this work, we propose FedSSO, a server-side second-order optimization method for federated learning (FL). In contrast to previous works in this direction, we employ a server-side approximation for the Quasi-Newton method without requiring any training data from the clients. In this way, we not only shift the computation burden from clients to server, but also eliminate the additional communication for second-order updates between clients and server entirely. We provide theoretical guarantee for convergence of our novel method, and empirically demonstrate our fast convergence and communication savings in both convex and non-convex settings.
Cooperative Policy Learning with Pre-trained Heterogeneous Observation Representations
Dec 24, 2020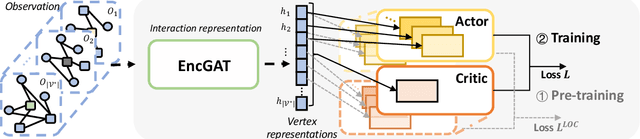
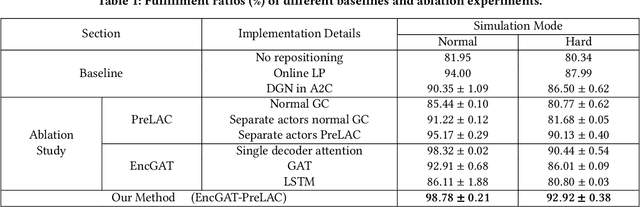
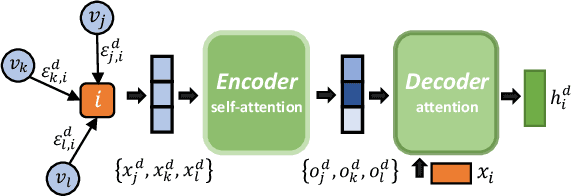

Multi-agent reinforcement learning (MARL) has been increasingly explored to learn the cooperative policy towards maximizing a certain global reward. Many existing studies take advantage of graph neural networks (GNN) in MARL to propagate critical collaborative information over the interaction graph, built upon inter-connected agents. Nevertheless, the vanilla GNN approach yields substantial defects in dealing with complex real-world scenarios since the generic message passing mechanism is ineffective between heterogeneous vertices and, moreover, simple message aggregation functions are incapable of accurately modeling the combinational interactions from multiple neighbors. While adopting complex GNN models with more informative message passing and aggregation mechanisms can obviously benefit heterogeneous vertex representations and cooperative policy learning, it could, on the other hand, increase the training difficulty of MARL and demand more intense and direct reward signals compared to the original global reward. To address these challenges, we propose a new cooperative learning framework with pre-trained heterogeneous observation representations. Particularly, we employ an encoder-decoder based graph attention to learn the intricate interactions and heterogeneous representations that can be more easily leveraged by MARL. Moreover, we design a pre-training with local actor-critic algorithm to ease the difficulty in cooperative policy learning. Extensive experiments over real-world scenarios demonstrate that our new approach can significantly outperform existing MARL baselines as well as operational research solutions that are widely-used in industry.